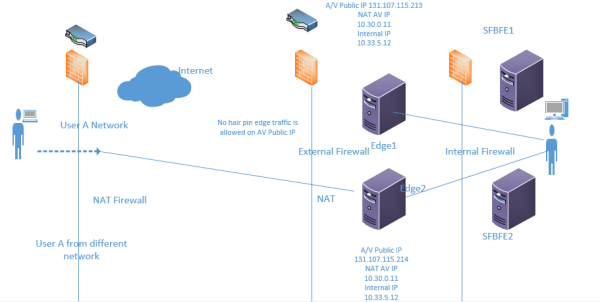
Mailbox replication service is the service responsible for moving the mailboxes,mailbox imports,mailbox exports and restore requests.
This article focuses on the migration status of the migration batch in Exchange 2016.
The move request statistics can be viewed by running the below command
Get-MoveRequestStatistics | Select DisplayName,StatusDetail,PercentComplete
Below were the status reasons of the migration notified for delayed migration batches:
Stalledduetotarget_dataguaranteewait:
From Exchange 2010 there is an Data Guarantee API that is used by Mailbox Replication service (MRS) to check the health of the database copy architecture based on a defined setting of the database.
This API is called by the MRS to see the following information:
Check Replication Health – Confirm that the prerequisite number of database copies is available.
Check Replication Flush – Confirm that the required log files have been replayed against the prerequisite number of database copies.
After this message If a Satisfied response is returned within the 15 minute stalling period, MRS will automatically resume the move request.
This is usually triggered during the move request to determine the health of the target database copies to which the mailboxes are moving from the legacy servers.
If the Data Guarantee API returns a NotSatisfied or a Retry response, MRS will queue the move request and retry the query every 30 seconds.
The parameters controlling these values can be seen in “MSExchangeMailboxReplication.exe.config” file located at “C:\Program Files\Microsoft\Exchange Server\V15\Bin”
Parameter Name Default Min Max
DataGuaranteeCheckPeriod 00:00:05 00:00:01 02:00:00
DataGuaranteeTimeOut 00:10:00 00:00:00 12:00:00
DataGuaranteeLogRollDelay 00:1:00 00:00:00 12:00:00
DataGuaranteeRetryInterval 00:15:00 00:00:00 12:00:00
DataGuaranteeMaxwait 1.00:00:00 00:00:00 7:00:00
EnableDataGuaranteeCheck True False True
Stalledduetotarget_mdbreplication:
This value is also returned from Data Guarantee API on checking the replication health of the target database copies if they are member of DAG and have database copies.
We might get this message if the MRS service is waiting to get this information from the target server about the replication status of the database copies.
So in this case the passive copy must be:
1)Healthy.
2)Must have a replay queue with 10 mins of replay lag time.
3)Have a copy queue length less than 10 logs.
4)Have an average copy queue length less than 10 logs.
Below are the parameters controlling in the msexchangemailboxreplication config file:
mdb latency health threshold
mdbfairunhealthylatencythreshold
mdbhealthyfairlatencythreshold
mdblatencymaxdelay
So at the end all the database copies must be healthy if we are randomly distributing mailboxes to the target destination.
Stalledduetohigherpriorityjobs:
We might get this status if the Exchange server Workload management introduced from Exchange 2013 is making the exchange system resources busy on other exchange operations and hence the move requests are affected.
First preferred option is we can submit the new move requests by modifying the Priority to emergency or highest by running the below command.
New-MoveRequest -Identity Mailbox -TargetDatabase “DB Name” -BatchName Test -Priority Highest
StalledduetoCI:
This is caused due to Content Indexing on the database copies, so to solve this by turning it off on the Mailbox Database till the migration is complete for that DB where the mailbox resides.
To turn it off run the below command :
Set-MailboxDatabase “your mailbox database” -IndexEnabled:$False
Note: This should be re-enabled once the migration has completed
This error might not happen in Exchange 2016 environments since the indexing process has been completely changed from Exchange 2016.
Stalledtotarget_disklatency:
This might happen if there are any issues in the disk performance ,causes the disk latency ,the response time from the source is getting high and the migration batches are getting timed out. This delays the movement of the mailboxes.Should start checking the target exchange 2016 disk performance IOPS etc. If we get this then there is some serious problems in the exchange 2016 performance .And this depends on the designed storage architecture, how the database copies are distributed with how many mailboxes in each copies.
Relinquishedwlmstall:
We might get this because of large delays due to unfavorable server health or budget limitations.
In most practical cases we can notice this status when moving a large mailboxes batch of size more than 5GB.
These are the parameters controlling this:
WlmThrottlingJobTimeOut
WlmThrottlingJobRetryInterval
The best solution for this is to move the large mailboxes on batches so that the system resources are sufficient to handle the migration.
Below are the major parameters that is controlling the migration on the Exchange 2016 servers:
“MSExchangeMailboxReplication.exe.config” file located at “C:\Program Files\Microsoft\Exchange Server\V15\Bin”
MaxRetries – 60, 0, 1000
MaxCleanupRetries – 480, 0, 600
RetryDelay – 00:00:30, 00:00:10, 00:30:00
MaxMoveHistoryLength – 5, 0, 100
MaxActiveMovesPerSourceMDB – 20, 0, 100
MaxActiveMovesPerTargetMDB – 20, 0, 100
MaxActiveMovesPerSourceServer – 100, 0, 1000
MaxActiveMovesPerTargetServer – 100, 0, 1000
MaxActiveJobsPerSourceMailbox – 5, 0, 100
MaxActiveJobsPerTargetMailbox – 2, 0, 100
MaxTotalRequestsPerMRS – 100, 0, 1024
Important tips to note down before migration:
1)Ensure there is no file level antivirus running on the migrating target servers.
2)Copy a 1GB file from the source server to the target server and verify the copy speed to ensure there is no network issues.
3)Make sure there is no backup jobs running during the migration batch period.
4)Better to initiate a small migration batch first of say 500 users and then open the perfmon during this period and monitor the memory,cpu,storage to make sure the resources are sufficient.
Note: Do not modify any values in the MSExchangeMailboxReplication.exe.config for any reasons. Better to open a call with Microsoft if any issues is identified in the maibox migration batches.
Thanks & Regards
Sathish Veerapandian
MVP- Office servers and Services